おかげさまで目の調子は徐々に良くなってきました。いろいろと機材も増えたので、そろそろ屋外&スタジオでポトレ撮影をしたいなぁ・・・などと考えています。被写体の女子の皆さん、よろしくお願いいたします。
Web UI を使わずに Stable Diffusion で画像生成
さて、相変わらず画像生成 AI「Stable Diffusion」でいろいろ遊んでいますが、ハイスペック PC を調達(自作)しないかぎりローカル環境では遅くて使い物になりませんし、無償版の Google Coraboratory で Stable Diffruison Web UI を使おうとすると警告が表示されたりで、いろいろ制約があって困りものです。
そこで、ちょっと調べてみたところ、どうやら Stable Diffruison Web UI さえ使わなければ Google Coraboratory で警告が出ることはないことが判明しました。というわけで、ネット上のいろいろな記事や動画を参考に、バッチ処理的にコマンドだけで Stable Diffsuion による動画生成を行ってみました。
コマンドだけで実行する場合のメリット・デメリット
Web UI を使わずにコマンドだけで実行する場合のメリットは「処理が速い」ことです。Web UI を使ったことがある人ならご存知と思われますが、Web UI が立ち上がるまで諸々のインストールを含めて 10 分弱かかります。ちょっと使いたいという場合にはこれは最大のネックです。
いっぽうデメリットは「Web UI が提供する豊富な機能が利用できない」点です。このためこの方法は本格的な画像生成を行うには不向きです。ちょっと試してみたいとか、モデルに依存しない簡単なテストをしてみたいという用途に向いています。もちろん、「無償版の Google Coraboratory で手軽に遊びたい」という方にも最適です。
Web UI を使わないコマンドの例
コマンドの入力と保存
Web ブラウザで Google Coraboratory を開いて「ノートブックを新規作成」を選びます。

新しいノートブックが開くので、ノートブック名を変更します。

ここでは batch.ipynb としました。

ノートブック上にはコードを記入する領域(セル)が1つだけ設置されています。画面上部メニューの「+コード」をクリックすることでコードセルはいくつでも追加できます。

このサンプルではコードセルを2つ使用しますので「+コード」をクリックしてセルを1つ追加しておきます。

まず、Stable Diffusion を起動するコマンドを入力します。ここでは以下のコマンドを使用します。*1
!pip install diffusers transformers scipy ftfy accelerate import torch from diffusers import StableDiffusionPipeline model_id = "SG161222/Realistic_Vision_V2.0" pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16) pipe = pipe.to("cuda") google_drive_dir = 'drive/' base_file_name = 'test1' !cat /proc/uptime | awk '{printf("残り時間 : %.2f", 12-$1/60/60)}'
最初のコードセルに上記のコマンドをコピペします。

次に、画像生成のためのプロンプトと実行コマンドを入力します。ここでは、サンプルとして下記のコマンドを使用します。
# プロンプト prompt = "Japan, a normal man, yo 40, around here, casual clothes that don't look good, bald" n_prompt = "(nsfw:1.3),extra fingers,bad anatomy,paintings,sketches,poorly drawn face,extra limbs,extra arms,extra legs,malformed limbs,long neck" # 画像の生成、保存、表示 image = pipe(prompt, negative_prompt=n_prompt, guidance_scale=7.5, num_inference_steps=50, height=768, width=512).images[0] image.save(f"man.png") image
2番目のコードセルに上記のコマンドをコピペします。

ランタイムのタイプを GPU に設定する
ランタイムメニューで「ランタイムのタイプを変更」を選択します。

ノートブックの設定ダイアログの「ハードウェアアクセラレータ」を「GPU」に設定します。
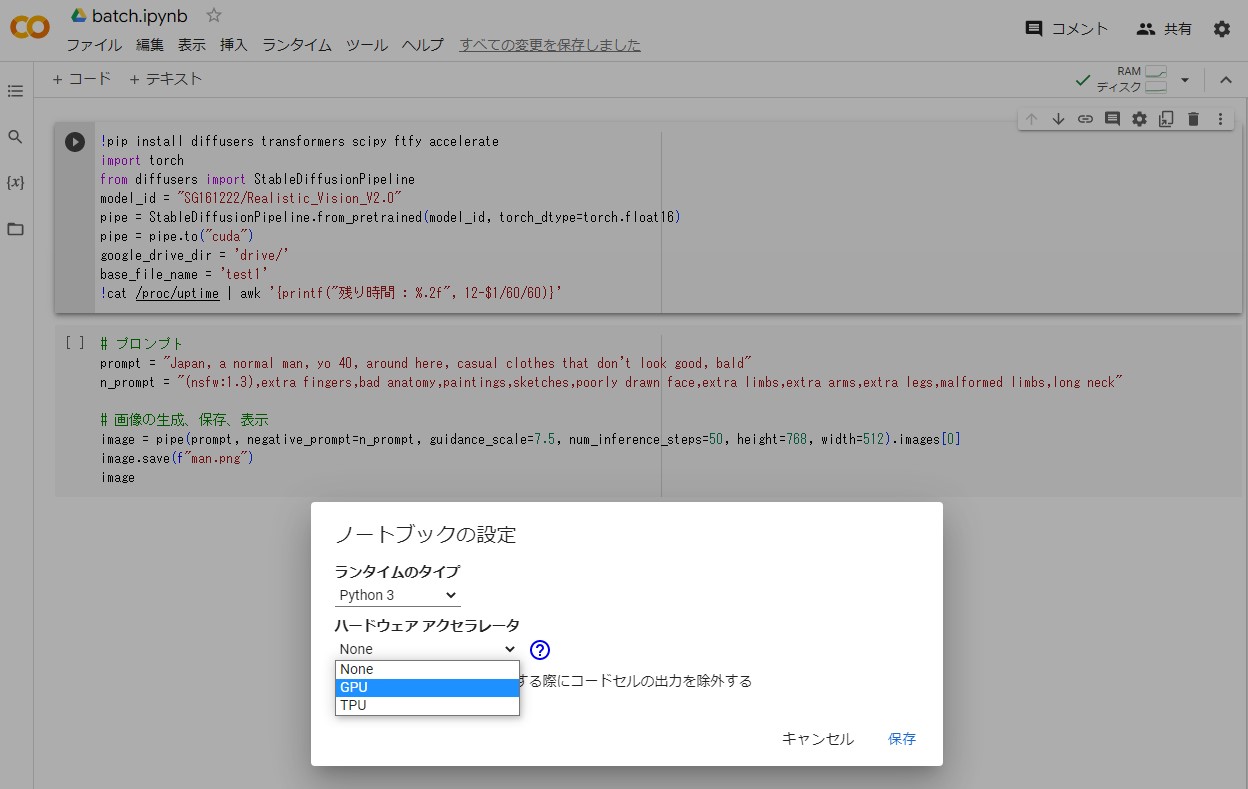
なお、「GPUのタイプ」は「T4」のままとします。設定を終えたら「保存」をクリックします。

ここまで入力できたら、ファイルメニューの「保存」を選んでファイルを保存しておきます。

コマンドの実行
最初のコードセルの三角アイコンをクリックしてコマンドを実行します。

コマンドが終了するまで(三角アイコンの回転が止まるまで)待ちます。

コマンド実行は数分で終了します。

画像の生成
2番目のコードセルの三角アイコンをクリックしてコマンドを実行すると画像生成が開始されます。

このサンプルでは十数秒で画像生成が終了します。生成された画像は右クリックしてファイルに保存できます。

さらに三角アイコンをクリックすることで、次々に別の画像を生成することができます。

必要に応じてプロンプトを変更すれば様々な画像が生成できます。

セルを追加すれば複数画像の同時生成も可能
さらにコードセルを追加して画像生成コマンドをコピペすることで複数画像を同時に生成することができます。

関連記事
アジア人女性(日本人女性を含む)の画像生成に適した学習モデル BRA V5 を使用し、さらに各種の機能追加を行った改良版のソースコードを使った記事を続編として投稿しました。あわせてご覧ください。
pepeprism.hatenablog.com