無償版の Google Coraboratory でお手軽に Stable Diffsuion による動画生成を楽しむ方法について記事を投稿したのですが、評価ゼロという世間の厳しい目にさらされて「やっぱり普通のおじさんの画像生成をサンプルに取り上げたのが不味かったか」と反省している今日この頃です。
というわけで、今回は「奇麗なお姉さん」の画像を手軽に生成するサンプルコードを例示することにします ( 笑 ) 。
Web UI を使わずに Stable Diffusion で奇麗なお姉さんの画像を生成する
サンプルコードの変更・追加 ( 2023-06-08 更新 )
奇麗なお姉さんの画像生成を行うにあたって、下記の変更・追加を行いました。
- 生成した画像ファイルを Google Drive の任意のフォルダに保存できるようにしました。コマンドの folder= の指定 *1 を変更することで任意のフォルダを指定できます。
- 生成した画像のファイル名が重複しないように ( 一意になるように ) ファイル名を ”学習モデル名"+ "@" +"生成年月日時分秒 ( 小数点以下を含む ISO 形式 ) " + "_" + "seed値" + ".png" として保存するように変更しました。
【例】sinkinai-Beautiful-Realistic-Asians-v5@2023-06-07T18_22_21.033371_2552175417807081197.png
- 学習モデルとして BRA V5 ( Beautiful Realistic Asians v5 ) を使用します。
- 画像生成の部分を関数(メソッド)化して、引数として以下のパラメータを指定できるようにしました。
| 引数 | 引数の意味 | 備考 |
|---|
| prompt | プロンプト | |
| negative_prompt | ネガティブプロンプト | |
| height | 画像の高さ | 単位:ピクセル |
| width | 画像の幅 | 単位:ピクセル |
| guidance_scale | プロンプトの重み | 値が大きいほどプロンプトを厳密に適用 |
| num_inference_steps | ノイズ除去ステップ数 | 値が大きいほど品質が向上する |
| seed | seed 値 | 任意の整数、同じ値を指定すると同じ傾向の画像が生成される。-1 を指定するとランダムな値になる。 |
- NFSW ( Not Safe For Work, 職場閲覧注意 ) フィルターを無効化して NFSW に類する画像を表示できるようにしました。*2
- 生成された画像に seed 値を表示するようにしました。seed 値を同じ値に設定することで類似画像を生成できるようになります。
サンプルコードの改訂 ( 2023-06-22 追記 )
Stable Diffusion の内部処理に変更があったようで、前項 5 番目の NFSW フィルターの無効化処理でエラーが発生するようになりました。そこで NFSW フィルターの無効化処理を改訂して対応いたしました。すでにコードをダウンロードしている方は、新しいコードへの差し替えをお願いします。
未実装機能
以下の機能はまだ実装できていません。今後の課題とします。
- アップスケール機能(高解像度化)には対応できていません。
- VAE には対応できていません。
- LoRA には対応できていません。
コマンドの入力と保存
Web ブラウザで Google Coraboratory を開いて「ノートブックを新規作成」を選びます。ノートブック名は BRAV5_Batch.ipynb のように変更します。なお、Google Coraboratory の操作方法についてはここでは省略します。前回の記事を参考にしてください。
pepeprism.hatenablog.com
このサンプルではコードセルを2つ使用しますので「+コード」をクリックしてセルを1つ追加してください。
まず、Stable Diffusion を起動するコマンドを入力します。ここでは以下のコマンドを使用します。なお、画像を保存する Google Drive のフォルダの指定はユーザの環境に合わせて変更してください。
model_id = "sinkinai/Beautiful-Realistic-Asians-v5"
folder = 'drive/MyDrive/data'
!pip install diffusers transformers scipy ftfy accelerate
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
device = "cuda"
pipe = pipe.to(device)
pipe.safety_checker = lambda images, **kwargs: (images, [False] * len(images))
def drawPicture (prompt, negative_prompt, height, width, guidance_scale, num_inference_steps, seed) :
import random, sys, datetime
seedValue = random.randint(0,sys.maxsize) if seed == -1 else seed;
generator = torch.Generator(device).manual_seed(seedValue)
image = pipe(prompt, negative_prompt=negative_prompt, height=height, width=width, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps, generator=generator).images[0]
path = folder + "/" + model_id.replace('/', '-') + "@" + datetime.datetime.now().isoformat() + '_' + str(seedValue) + ".png"
image.save(path)
print('seed = ' + str(seedValue))
return image
最初のコードセルに上記のコマンドをコピペします。

次に、画像生成のためのプロンプトと実行コマンドを入力します。ここでは、サンプルとして下記のコマンドを使用します。プロンプトとネガティブプロンプト、画像サイズなどの各種パラメータは必要に応じて書き換えてください。
prompt = "masterpiece, best quality,ultra high res,(photo realistic:1.4),1 girl, short hair, looking at viewer"
n_prompt = "Easy negatvie, (worst quality:2),(low quality:2),(normal quality:2), lowers, normal quality,((monochrome)),((grayscale)),skin spots, acnes, skin blemishes, age spot, nsfw, ugly face, fat, missing fingers, extra fingers, extra arms, extra legs, watermark, text, error, blurry, jpeg artifacts, cropped, bad anatomy, big eyes"
drawPicture (prompt=prompt, negative_prompt=n_prompt, height=768, width=512, guidance_scale=7, num_inference_steps=50, seed=-1)
2番目のコードセルに上記のコマンドをコピペします。

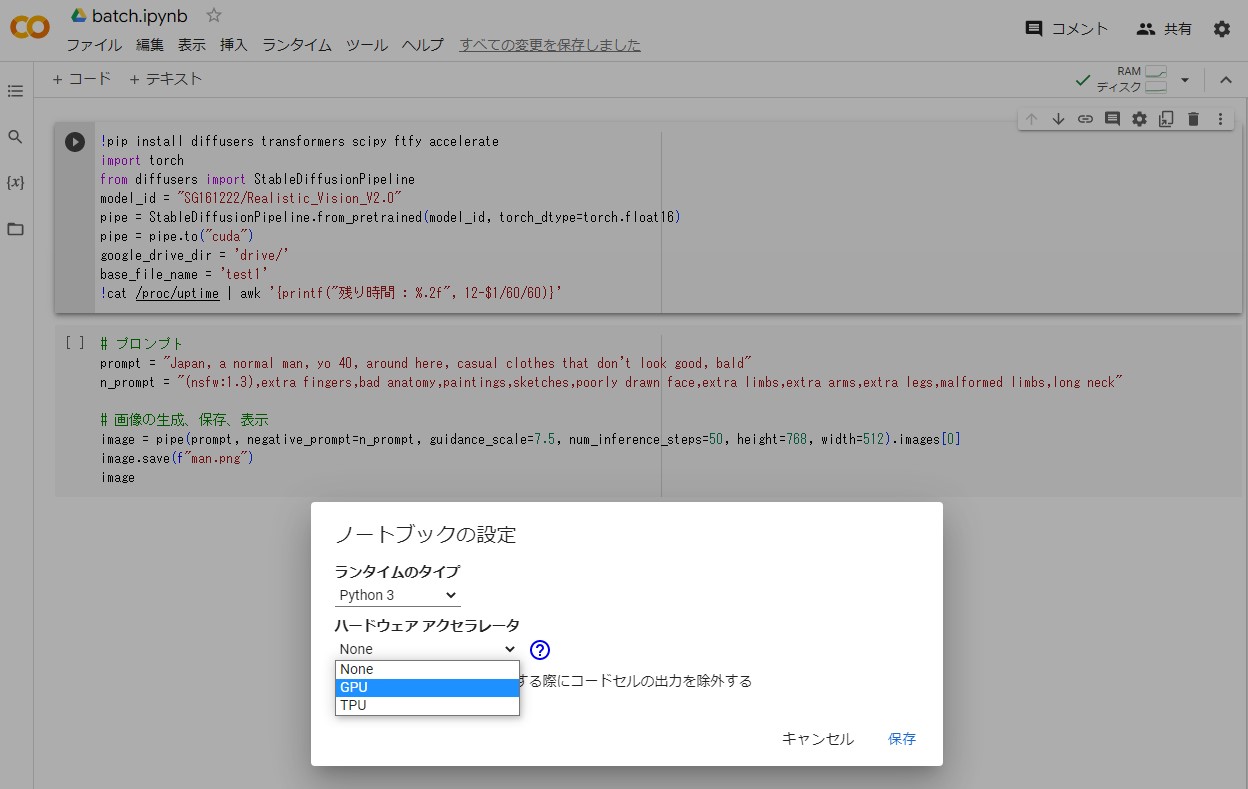
ランタイムのタイプを GPU に設定する
ランタイムメニューで「ランタイムのタイプを変更」を選択します。

ノートブックの設定ダイアログの「ハードウェアアクセラレータ」を「GPU」に設定します。なお、「GPUのタイプ」は「T4」のままとします。設定を終えたら「保存」をクリックします。

ここまで入力できたら、ファイルメニューの「保存」を選んでファイルを保存しておきます。

コマンドの実行
最初のコードセルの三角アイコンをクリックしてコマンドを実行します。

コマンドが終了するまで(三角アイコンの回転が止まるまで)待ちます。コマンド実行は数分で終了します。
画像の生成
2番目のコードセルの三角アイコンをクリックしてコマンドを実行すると画像生成が開始されます。

このサンプルでは十数秒で画像生成が終了します。

さらに三角アイコンをクリックすることで、次々に別の画像を生成することができます。

セルの追加による複数画像の生成
さらにコードセルを追加して画像生成コマンドをコピペすることで複数画像を同時に生成することができます。
画像の保存
画像の保存は下記のいずれかの方法で行うことができます。
画像を右クリック
それぞれの画像を右クリックして「名前を付けて画像を保存」を選択します。

サイドメニューのフォルダ表示
ノートブックの左サイドメニューのフォルダアイコンをクリックして画像が保存されているフォルダの中から画像ファイルを選んで右クリックメニューのダウンロードを選択します。

Google Drive を開いて画像が保存されているフォルダの中から画像ファイルを選んでダウンロードします。

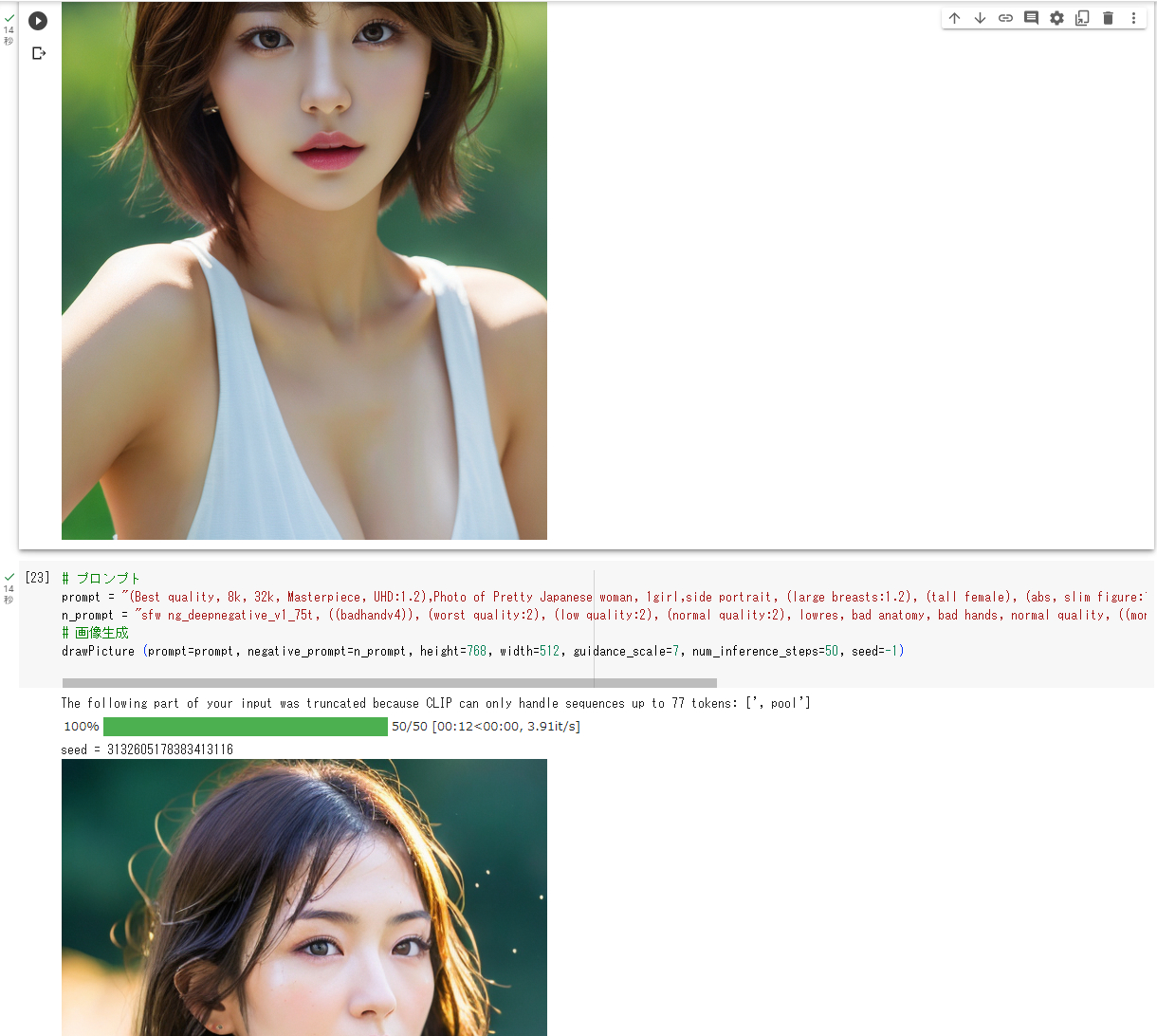
生成した画像のサンプル
今回のスクリプトを使用して生成した画像のサンプルを以下に掲げます(画像をクリックすると拡大表示されます)。なお、プロンプトは何パターンか作成しています。
脚注・コメント











































































 1シートライセンス 日本語パッケージ版 2大特典付き 写真編集 画像編集 ソフト")
 2シートライセンス 日本語パッケージ版 2大特典付き 写真編集 画像編集 ソフト")













SP XRジLD非球面(IF) タムロン社【並行輸入】")







")




































")
